When It Comes to Benchmarking ... Size Matters
Four Slices at Case Weight
Would you mind getting a little "nerdy" with me on the topic of benchmarking? During my travels this month, I've seen some eyebrow-raising decisions made around benchmarks that simply aren't representative or relevant, and I think it's important to expose the problem. Whether looking at financial, clinical or patient satisfaction benchmarks, an organization needs to compare itself to a robust peer group. Here at SHP, we refer to that size as an "n." I’d like to walk you through an example of how a small benchmark can compromise your decision making, and caution against using some of the self-appointed industry benchmarks that get thrown around out there.
Small benchmarks are just plain useless, if not harmful. Large national benchmarks are helpful, but have limitations. Oftentimes, the best benchmarks are found at the more granular level. Each time a benchmark gets sliced-and-diced, to arrive at the granular level, the comparison group becomes smaller at each pass. So, it's essential that the purveyor of those benchmarks start from a very large "n." I've put together an example that shows four different slices of the case weight metric.
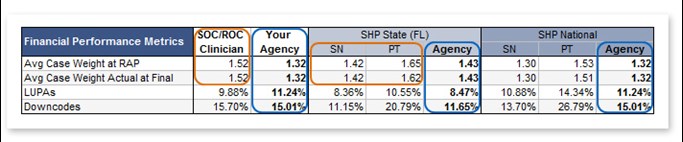
- Note that the agency matches the SHP national benchmark in all scores (circled in blue). Its case weight, LUPAs and down code rates are right in line with the national average. However, by looking at their Florida state benchmark, notice how much lower the agency's case weight is while its LUPAs and down codes are both higher. Arriving at the state benchmark took a large cut out of the national comparison data.
- Now look at the agency's average start-of-care case weight shown by clinician (circled in orange). While this clinician's scores are right in line with the SHP national benchmark for physical therapists, they're low for physical therapists in Florida and high for skilled nurses. Obtaining this metric required three more slices of the data.
The example demonstrates how vitally important it is to use reputable benchmarks that are relevant and representative, so business intelligence decisions are properly informed. An over-reliance on a national score could have misled this agency into an unwarranted sense of complacency or influenced it to allocate resources where they're not needed. That problem would have been compounded had the comparison group been too small. So, yes, when it comes to benchmarking, size matters.